- Access Finance
- Case Studies
-
Informing today's market
Financing tomorrow's trade
Soft Commodities Trader
Due to increased sales, a soft commodity trader required a receivables purchase facility for one of their large customers - purchased from Africa and sold to the US.
Metals Trader
Purchasing commodities from Africa, the US, and Europe and selling to Europe, a metals trader required a receivables finance facility for a book of their receivables/customers.
Energy Trading Group
An energy group, selling mainly into Europe, desired a receivables purchase facility to discount names, where they had increased sales and concentration.
Clothing company
Rather than waiting 90 days until payment was made, the company wanted to pay suppliers on the day that the title to goods transferred to them, meaning it could expand its range of suppliers and receive supplier discounts.

Get Trade Finance
Informing Today’s Market, Financing tomorrow’s Trade.
-
- Case Studies













Optical Character Recognition


Download our Tradetech Whitepaper
Accelerating trade digitalization to support MSME financing

Content
Optical Character Recognition (OCR) is a technology that converts scanned or printed text images, such as handwritten or printed documents, into machine-encoded text that can be processed further. OCR is a common method of digitizing printed texts so that they can be electronically edited, searched for and used in other digital processes.
Potential benefits for MSMEs
OCR technology allows paper documents to be scanned and converted into digital formats. As it seems clear that paper in global trade will not go away quickly, OCR provides a means for interacting with clients who can‘t or won‘t deliver the data in a structured format, and this allows the user to easily find any kind of document simply by typing the details into a search bar, rather than searching through boxes of unorganized documents. In an industry with 4 billion pages in circulation and millions of hours spent on examining these pages, OCR technology is acting like a bridge between technology and processes that can only be done by hand. For most MSMEs, the benefits of OCR will be experienced indirectly through lowered costs due to less manual input.
Use cases
According to the ICC Global Survey 2020, 28 per cent of banks are using OCR for data extraction and creating searchable documents, including big banks active in trade finance, such as HSBC and Standard Chartered. OCR is also being used by various fintech companies active in the trade digitalization space, often in conjunction with other digital technologies, in particular artificial intelligence (AI) and machine learning (ML).
Traydstream, for example, is a cloud-based solution that digitizes documentary trade (letters of credit, documentary collections and open account financing) into a machine-readable format, using ML to automate the scrutinizing, clause-matching and rules- and compliance-checking processes.
Nabu is another fintech company that uses OCR, natural language understanding and deep learning to digitize the manual processes of trade finance.
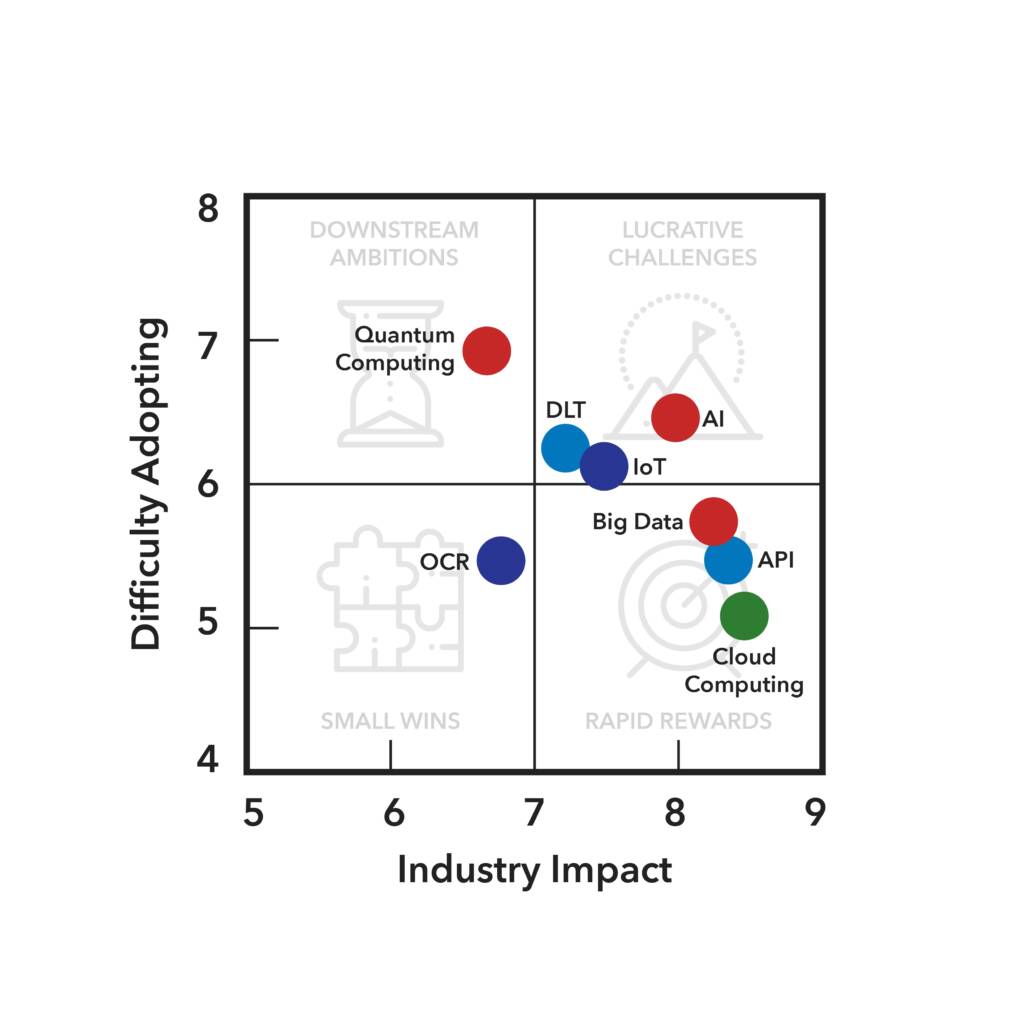
Addressing OCR challenges
Unlike most of the other technologies discussed in this publication, it is the technology itself that seems to be the greatest challenge for OCR. The technology is not perfect, the best you can get is 85-90 per cent effective. Furthermore, these accuracy challenges are only exacerbated for non-Latin or non-romance languages, meaning that all documents require assistance by human intervention. This need to continue allocating human resources to the task of document review drastically reduces the expected benefits of the technology, and this may affect the likelihood of its corporate adoption, given that integrating these solutions into existing processes of banks and corporates can be expensive. These concerns are exacerbated by a seeming lack of motivated talent in the field. Most people working in computer vision lately are focusing on health and medical imagery, making it difficult to build great teams with brilliant minds for trade applications.
OCR is serving as a temporary bridge between the paper world of yesteryear and a digital future.
To overcome this challenge, it would logically be necessary to improve the technology; however, OCR is unique. It is in a strange situation where its success will lay the groundwork for its own obsolescence. OCR is serving as a temporary bridge between the paper world of yesteryear and a digital future. It will create more adoption of new technologies by banks to improve their operational processing, allowing them to convert paper records to digital ones. This will further empower trade chain ecosystems to start with digital data at the source, which renders OCR useless. Ultimately, a digital trade utopia has no need for OCR.
Publishing Partners
- Tradetech Resources
- All Tradetech Topics
- Podcasts
- Videos
- Conferences